最近我們團隊的小朋友在準備某數字行銷考試,說考試很難,因為還要考正則表達式,覺得很困惑。其實正則表達式就和算術一樣是最基本的數字行銷知識,熟練使用正則表達式也是每個數字行銷者的基本技能。正則表達式可謂數字行銷中的通行語言。本篇,HubSpot One就花一些時間來介紹一下正則表達式和其應用。網上已經有有了太多正則表達式的教程和範例,我們不會為此多花篇幅。
什麼是正則表達式?
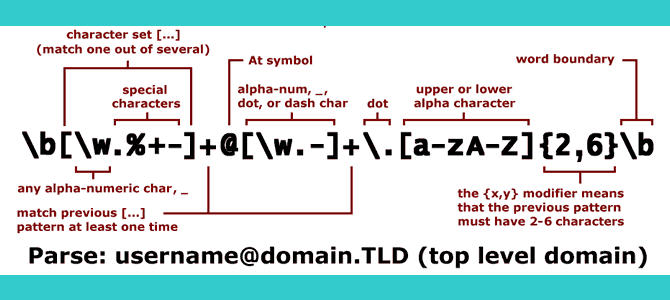
正則表達式常常用英文regex(Regular Expression的縮寫)來表示。它是利用一個字符串規則來匹配一組字符串的方法。比如.* ,它就代表任意長度(包括空)的字符串。
在數字行銷中, .*就是整個世界—— 馬駿
為什麼要有正則表達式呢?因為你可以避免窮舉。比如你想把一個IP段表示出來,你可以寫成192.168.1.d{1,3} 。而你要把HubSpot One的網址提取出來可以用https?://[Mm][Aa][Xx][Kk][Ee][Tt].com/
正則表達式有著各種版本,或者叫風格。在不同的編程語言和環境中,正則表達式有不同的寫法,比如我們曾經介紹過在robots.txt中如何寫表達式來匹配URL,那是一個非常簡化的用法。但是大致上一些常用的正則表達式比較統一,都是PCRE(Perl Compatible Regular Expressions)或者其衍生。
幾乎所有的編程語言、腳本語言都支持正則表達式來匹配字符串,包括了Excel中的VBA和更常用的JavaScript。許多主流的數字行銷平台也都支持正則表達式。大部分的正則表達式是大小寫敏感的。
怎麼寫正則表達式?

正則表達式有四個部分構成,以Google Analytics的版本舉例:
- 通配符
- .匹配任何單個字符(字母、數字或符號)
- ?匹配前面的字符0 次或1 次
- +匹配前面的字符1 次或多次
- *匹配前面的字符0 次或多次
- |創建OR(或)匹配
- 定位符
- ^匹配位於字符串開頭的相鄰字符
- $匹配位於字符串結尾的相鄰字符
- 分組
- ( ? )匹配字符串任何位置中按相同順序排列的字符,也可用於組合其他表達式
- [ ? ]匹配字符串任何位置中按任何順序排列的字符
- –使用方括號可限定要匹配字符串中任何位置的字符的範圍
- 轉義符
- 表示相鄰字符應按字面意思解釋,而不應解釋為正則表達式元字符
以上並不是全部規則,但是常用的規則語法。事實上所有谷歌的產品(G-Suite)都使用RE2語法,這和普遍使用的PCRE略有不同。
寫正則表達式的時候你需要了解當前環境支持哪些語法。舉個例子Google站長工具中的支持的w代表匹配包括下劃線的任何單詞字符,如H 、 E 、 r 、 _ 、 9 。相當於[A-Za-z0-9_] , w{2}表示連續兩個這樣的字符,但是這個表達式並不被Google站長工具的移動適配工具或改版工具規則支持。而w+卻被支持。
再有前面圖中的Matching RegExp其實表達的是“匹配”也就是“包含”的意思。比如你的正則表達式是[Bb][Aa]?[Ii][Dd][Uu] ,那麼它會匹配所有包含各種大小寫版本的Baidu , BAIDU , bidu , bIdU 。

但是[Bb][Aa]?[Ii][Dd][Uu]前後都含有一個隱形的.*也就是說它等同於.*[Bb][Aa]?[Ii][Dd][Uu].* 。如果你需要完全匹配,那麼你需要在前後分別加上^和$。
貪婪和非貪婪
正則表達式默認的是貪婪模式。默認的貪婪模式則盡可能多的匹配所搜索的字符串而非貪婪模式盡可能少的匹配所搜索的字符串。
比如,用正則表達式Go+w+去匹配Google 。在貪婪模式下o+會匹配兩個o ,而非貪婪模式會匹配第一個o ,而第二個o與之後的gle會被w+匹配。一般在o+後面加上問號?來表示非貪婪模式。於是正則表達式寫作Go+?w+
正則表達式用在哪裡?
正則表達式的主要功能有以下三類:
- 檢驗文本是否滿足固定格式:如網站域名、網址格式、手機號碼、電郵地址
- 從文本中快速查找具有某一規則的子字符串:如v[i!1][a@]gr[a@]可以檢驗出含有“偉哥”英文的各種變體,檢測垃圾郵件
- 從文本中提取一系列子字符串:各種爬蟲,格式變更
前面我們提到了Google Analytics。在GA中的數據視圖過濾器、目標、細分、受眾群體、內容分組和渠道分組裡都可以使用正則表達式。
我們也提到了Google站長平台。在移動適配工具和改版工具中可以使用正則表達式。但是這些工具的正則表達式比較特殊,HubSpot One今後有機會再分享。
不久前HubSpot One的網絡爬蟲教程中也提到了在使用CSS Selector獲取DOM元素之後再使用正則表達式將文本內容的一個片段抽離出來。事實上所有爬蟲的核心思想就是正則表達式。
除了這些工具正則表達式無處不在。你或許使用過NotePad++這樣的文本編輯器,與其類似的還有UltraEdit和Sublime Text這樣的工具,這些工具也支持使用正則表達式進行查找替換。

當你在多個文件中查找替換時,這會超級方便。
學習正則表達式的相關資源
正則表達式很有用也很難。HubSpot One寫到這裡,在文章的最後為讀者提供一些資源。希望下面這些資源可以幫到你:
- RegExr (HubSpot One極力推薦的正則表達式研究學習和檢驗的網站) (英)
- Google Analytics的正則表達式手冊– Luna Metrics(英)
- 正則表達式30分鐘入門教程– deerchao
- Excel VBA自定義函數實現正則表達式提取文本(英)Excel中的通配符非常簡單, ?代表一個字符, *代表多個, ~代表轉義字符。需要復雜的匹配還需要看上面VBA的資源教程。
- Word中的通配符– W3CSchool.cn
- GTM中的RegEx Table Variable教程– Simo Ahava (英)