什麼是結構化數據?
結構化數據的概念起源於搜索引擎對於文字內容理解上的缺失。由於網路上最大量的訊息來源是文字,而文字卻是相當隨意的,缺乏邏輯性和結構性這讓搜索引擎的小機器人發生了困惑。在2011年谷歌,微軟,雅虎和Yandex這幾家搜索引擎巨頭坐到了一起探討如何改進對互聯網訊息的進一步理解。
Schema.org
探討的結果便是大家擬定一個協議,這就是我們現在看到的Schema.org的框架。通過這個協議,我們使用標籤,將我們的內容從文本上賦予結構性。舉個例子來說,假設你的網站有一個頁面是一部電影的介紹,你可以洋洋灑灑寫1000字,但是小機器人讀完還是不明白這部電影片名叫什麼,導演是誰,公映年份,主演卡斯。如果小機器人無法理解,那導致的後果便是搜索引擎提供的內容質量難以提升。 Schema.org推出不過幾年,即使在美國,使用的網站仍然很少。根據SearchMetrics的統計,大概只有0.3%的網站,也就是大約三百分之一。從排名上我們可以看到對結構化數據進行了優化的網站在各關鍵詞的平均排名要先於未進行優化的網站4個名次(21 vs 25)。另外,36%的谷歌查詢包含至少一個富文本結果,如下的電影《阿凡達》搜索結果中(SERP)我們可以做大概了解:
搜索英文Avatar《阿凡達》的谷歌搜索結果 排名第一的IMDB就使用了schema.org結構化數據。查閱其代碼我們可以看到:
<div id=”pagecontent” itemscope itemtype=”http://schema.org/Movie”>
可見,這個頁面在這裡定義了一個電影的item。所以在SERP上會列出關於此影片的其他訊息,因為搜索引擎已經理解這個頁面的內容。結構化數據目前使用的網站還不多,所以先一步使用結構化數據會使自身處於相當有利的位置。
什麼樣的網站需要結構化數據?
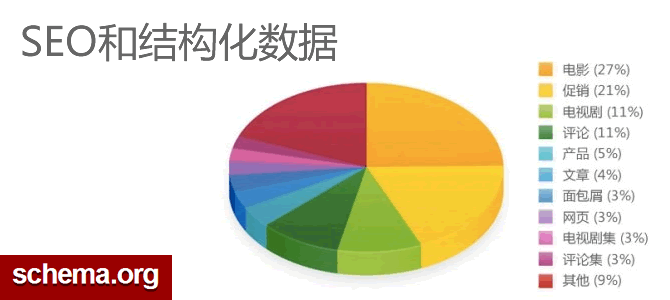
Schema.org在各網站的用途分類 統計表明使用Schema.org結構化數據框架的網站還是分類比較集中的。目前主要集中在影視行業,還有促銷和評論等方面。事實上,幾乎所有的網站都可以進行結構化數據集成。它可以將你數據庫中的訊息無損地展現到前端頁面上。 Schema.org規定最基本的元素是Thing。只要你的網站提供的是一個Thing就可以用結構化數據進行描述。那麼我們接下來用3分鐘時間舉一個例子,如何用結構化數據來描述你的Thing。
Schema.org集成簡易教程
第一步,定義一個itemscope的域
這一步是要告訴小機器人你所要描述的Thing開始了。假設你的生意是開一個髮廊(⊙o⊙)…那麼你要在該訊息的標籤處添加itemscope並且把Thing的類型設置成“HairSalon”。
<div itemscope itemtype=”http://schema.org/HairSalon” > <h1>河馬髮廊</h1> <span>河馬髮廊是一個不存在的髮廊,這裡僅用於說明結構化數據的集成。 </span> <span>營業時間:週一到週日,上午10點到晚上10點。 </span> <span>門店地址:浣熊市河馬路98號。郵編:123456</span> <span>電話:123-4567-8890</a> <a href=”http://hemasalon.com/hema_salon.html”>網址</a> </div>
第二步,添加Item的各屬性
接下來我們添加關於你的生意的各個屬性訊息的集成標籤。我們可以看到這些屬性和schema.org裡所定義的類型一致。
<div itemscope itemtype=”http://schema.org/HairSalon” > <h1 itemprop=”name” >河馬髮廊</h1> <span itemprop=”description” >河馬髮廊是一個不存在的髮廊,這裡僅用於說明結構化數據的集成。 </span> <span itemprop=”openingHours” datetime=”Mo, Tu, We, Th, Fr, Sa, Su 10:00-22:00″ >營業時間:週一到週日,上午10點到晚上10點。 </span> <span itemprop=”address” >門店地址:浣熊市河馬路98號。郵編:123456</span> <span itemprop=”telephone” >電話:123-4567-8890</a> <a href=”http://hemasalon.com/hema_salon.html” itemprop=”url” >網址</a> </div>
第三步,進一步添加結構化訊息
之前我們看到address這個屬性的內容是Text文本,實質上根據schema,搜索引擎期待(expected)的是一個address類型。這裡我們可以用另一類型PostalAddress來進一步細化。那麼我們在這個屬性上再添加一個itemscope域,並且按照PostalAddress來對地址進行描述:
<div itemscope itemtype=”http://schema.org/HairSalon” > <h1 itemprop=”name” >河馬髮廊</h1> <span itemprop=”description” >河馬髮廊是一個不存在的髮廊,這裡僅用於說明結構化數據的集成。 </span> <span itemprop=”openingHours” datetime=”Mo, Tu, We, Th, Fr, Sa, Su 10:00-22:00″ >營業時間:週一到週日,上午10點到晚上10點。 </span> <span itemprop=”address” itemscope itemtype=”http://schema.org/PostalAddress” >門店地址: <span itemprop=”addressLocality” >浣熊市</span> <span itemprop=”streetAddress” >河馬路98號。 </span> 郵編: <span itemprop=”postalCode” >123456</span> </span> <span itemprop=”telephone” >電話:123-4567-8890</a> <a href=”http://hemasalon.com/hema_salon.html” itemprop=”url” >網址</a> </div>
最後的話
Schema.org結構化數據是未來搜索引擎必不可少的元素,這是提高搜索引擎友好度,幫助搜索引擎理解網頁文本內容的最終出路。國內的搜索引擎雖然起步較晚但已經逐步開始接觸結構化數據方案。如Google也已經發布了部分的結構化數據樣式規範,詳見Google站長數據規範。大數據也是未來互聯網發展的趨勢之一。最後,如果你喜歡本文,期待你的寶貴留言。也希望你分享給你身邊的SEO們。