HubSpot One在去年介紹谷歌隱私沙盒的FLoC(Federated Learning of Cohort)時曾經評價“FLoC是谷歌當前最佳的答案”。但是僅過了不到一年,FLoC就被拋棄,轉而被Topics API取代。當時,行銷長曾經解釋因為這些Cohorts很容易被利用,成為瀏覽器指紋的彈藥來戕害用戶的隱私。那麼從我們行銷者的角度看,這其中的是非曲直又是什麼呢?困境在哪裡呢?
跨域跟踪,被逼到角落的無奈之舉
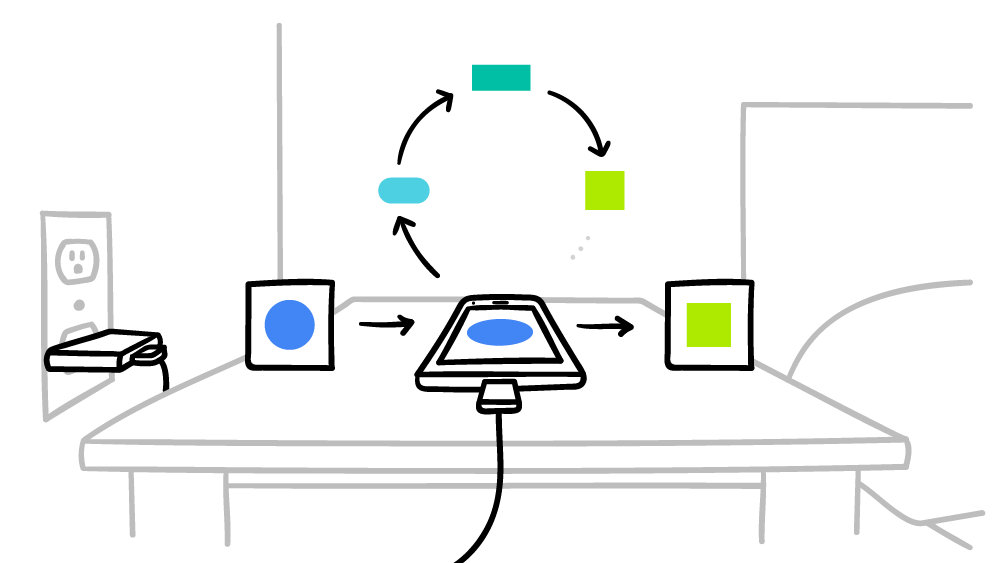
在Web端,我們要實現跨域跟踪,必須要在客戶端的本地有一個存儲介質。這個存儲介質過去一直是第三方Cookie。我們至少需要存一個客戶端的識別號,這樣我們就能夠跟踪這個瀏覽器整體的瀏覽歷史了。
當第三方Cookie和廣告技術供應商的服務器之間的通信被切斷之後,我們就不能了解該客戶端的瀏覽歷史,也不能對該瀏覽器的用戶進行識別或者貼標籤了。
所以這種普適的方法被淘汰後,廣告技術供應商就只能寄希望再下一層的瀏覽器API。至少暫時不需要再往下到操作系統層面。而恰好谷歌既是全球最大的廣告技術供應商又是市場佔有率最高的瀏覽器的開發方😉那就不用求人了。
這套API就是谷歌的隱私沙盒。
以汝之名,聯邦學習和FLoC
想出聯邦學習的點子是很自然的事。這好比我們去家具城買家具,不會把房間搬去,我們只需要量好尺寸去挑選定制即可。

聯邦學習也是一樣,它的精髓在於“數據不動算法動”。你不需要獲得終端用戶的PII(Personal Identifiable Information)訊息,你只需要把你的訓練算法推送到用戶終端。依靠用戶本地環境進行訓練,然後把訓練後結果,即更新後的模型參數加密回傳即可。
這麼看來聯邦學習是挺可靠的,用戶可以避免隱私的洩露。模型也可以不斷迭代,使得算法更加精準可靠。那麼問題究竟出在哪裡呢?
問題並沒有出在FLoC洩露了用戶的PII或瀏覽歷史,而是在於FLoC可以幫助廣告網絡辨識出單個用戶。
你的名字,Cohort ID集合
使用FLoC來投放的廣告和原來一樣都需要使用DMP來判斷Y/N的問題,都是需要競價。而廣告主出價的依據依然是該終端個體是否符合他們在DSP中預設的人群特性。
我們知道Cohort是通過聯合學習在本地計算出來並保存的,雖然FLoC的每個Cohort都至少有一千個個體,但是只用一個Cohort去邀約競價的話基本上跑不出量。因此會用一個包含多個Cohort的集合去代替以往的個體標籤集合。換句話說,原來一個叫做【男,35-40,已婚,北京,寵物,汽車】的個體會被替換成【vqe7te,34y0g3,123bqe,a3sg03】。
過於精準而產生的隱私漏洞
雖然Cohort vqe7te有2萬人,但是同時在這些Cohorts裡的個體就很少了。
MIT的Alex Berke和Dan Calacci進行了測試,發現5萬個家庭的9萬部設備在4週後就有高達95%的設備被唯一標識出來。
於是對於廣告網絡來說,他們可以記錄下該用戶訪問過其網絡下的各個網站並很好地跟踪這個用戶的行為。然後如果這裡面恰巧有一個該用戶登錄的網站,那麼在一些情形下廣告網絡甚至可能拿到PII並和該用戶的瀏覽歷史連結起來。是不是現在看來問題就嚴重了?
Topics API的補救
所以相信你現在能更好地理解為什麼Topics API需要進行6選3並加入噪音了。你也能夠理解為什麼Topics的話題數量看上去那麼少。因為多了意味著更容易暴露個體用戶。

聯邦學習在私有學習的時候可以很好地規避許多數據洩露的風險,比如在銀行業使用。但是在廣告科技中,當我們會暴露一些特徵訊息時,聯邦學習就顯得不那麼有效。這好比我們帶著這個尺寸去家具城的同時還會把我們家庭住址暴露,導致收到許多垃圾廣告,那就成為問題了。
所以,FLoC死不足惜!